Tecnologia•7 min de leitura
GPT-5.4 supera especialistas humanos em 83% das tarefas: a IA já não pratica, trabalha

A 5 de março, a OpenAI lançou o GPT-5.4 com um dado que não admite muita interpretação: no GDPval, o banco de provas que mede trabalho profissional real em 44 profissões, o modelo igualou ou superou especialistas humanos em 83% das comparações. Três dias depois, a Anthropic publicou que o Claude Opus 4.6 tinha identificado 22 novas vulnerabilidades no Firefox em duas semanas, 14 delas de alta severidade, e que a primeira foi encontrada em vinte minutos. Duas notícias distintas. A mesma mensagem.
GPT-5.4: o modelo que já não espera instruções a cada passo
A arquitetura do GPT-5.4 consolida algo que a OpenAI vinha construindo por partes: unificou as capacidades de raciocínio do GPT-5.2 com as de programação agentiva do GPT-5.3-Codex num único modelo. O resultado é um sistema que opera computadores de forma autónoma, navega aplicações sem supervisão e completa fluxos de trabalho complexos sem que ninguém precise de o guiar passo a passo.
Segundo a OpenAI, o GPT-5.4 tem 33% menos probabilidade de cometer erros em afirmações individuais do que o seu antecessor GPT-5.2, e as respostas completas contêm 18% menos erros. Os números de desempenho em ambientes profissionais são ainda mais impressionantes: no GDPval, que avalia trabalho bem especificado através de 44 profissões dos nove setores com maior contribuição para o PIB dos Estados Unidos, o GPT-5.4 alcançou 83% de correspondência com, ou superação do, critério de especialistas humanos, face aos 70,9% obtidos pelo GPT-5.2.
Para quem trabalha com documentos financeiros, apresentações ou análise jurídica, isto não é abstrato. Em modelos de investimento e banca, 87,3% dos avaliadores preferiu o GPT-5.4 face aos 68,4% que preferiam o GPT-5.2. A janela de contexto sobe para um milhão de tokens na API, o que permite processar contratos inteiros, repositórios de código ou históricos clínicos numa única interação.
A chave operacional está numa nova função chamada planeamento antecipado: antes de responder, o modelo mostra o seu plano de raciocínio. O utilizador pode redirecioná-lo a meio do processo sem começar do zero. Não é um detalhe menor. É o que diferencia um assistente de um colaborador.
| Métrica / Benchmark | GPT-5.4 | GPT-5.3-Codex | GPT-5.2 |
|---|---|---|---|
| GDPval (vitórias ou empates) | 83,0 % | 70,9 % | 70,9 % |
| SWE-Bench Pro (Public) | 57,7 % | 56,8 % | 55,6 % |
| OSWorld-Verified | 75,0 % | 74,0 %* | 47,3 % |
| Toolathlon | 54,6 % | 51,9 % | 46,3 % |
| BrowseComp | 82,7 % | 77,3 % | 65,8 % |
* Anteriormente reportado como 64,7%. O GPT-5.3-Codex atinge os 74,0% com um novo parâmetro da API que preserva a resolução original da imagem.
Claude encontrou no Firefox o que os humanos demoraram um ano a corrigir
Enquanto a OpenAI apresentava o seu modelo, a Anthropic publicava algo com uma dimensão diferente: não um número de benchmark, mas um caso real com consequências reais para centenas de milhões de utilizadores.
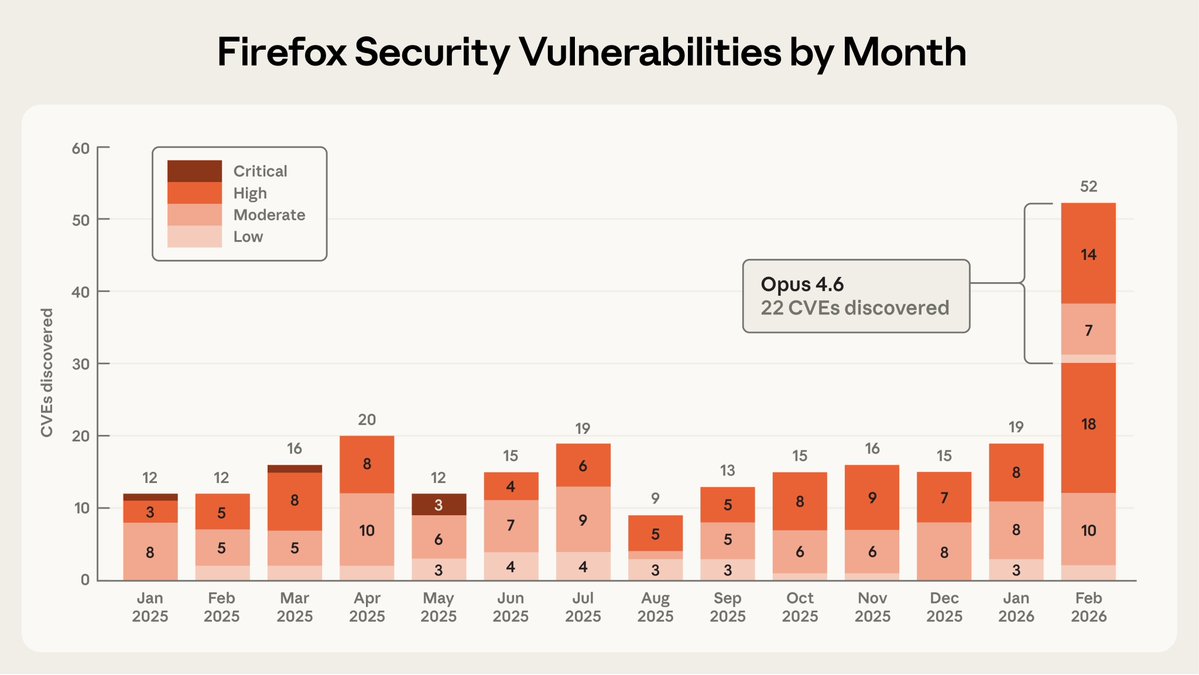
O Claude Opus 4.6 encontrou 22 vulnerabilidades no Firefox durante fevereiro de 2026, mais do que as reportadas em qualquer mês individual de 2025, e as suas correções chegaram aos utilizadores através do Firefox 148.0. Dessas 22, 14 foram classificadas como de alta severidade, o que representa quase um quinto de todas as vulnerabilidades dessa categoria corrigidas no Firefox ao longo de todo o ano de 2025.
O detalhe que mais circulou entre investigadores de segurança: após apenas vinte minutos de exploração autónoma, o modelo reportou ter identificado um erro de "uso após libertação" no motor JavaScript do navegador, que foi validado por um investigador humano num ambiente virtualizado antes de ser enviado à Mozilla.
Dos 112 relatórios totais que a Anthropic enviou à Mozilla, 22 resultaram em CVEs oficiais por falhas de segurança, enquanto os noventa restantes correspondiam a problemas não críticos como falhas de sistema e erros lógicos. A equipa analisou cerca de 6.000 ficheiros de código C++. A operação completa durou duas semanas.
Aqui está a parte que a Anthropic não sublinhou, mas que o relatório deixa escrita com clareza: o modelo é muito melhor a detetar falhas do que a explorá-las. Para testar as capacidades ofensivas do sistema, os investigadores tentaram que o Claude desenvolvesse exploits funcionais para as falhas descobertas, gastando aproximadamente 4.000 dólares em créditos de API em centenas de tentativas; o Opus 4.6 apenas conseguiu criar um exploit operativo em dois casos. Ambos funcionavam exclusivamente em ambientes de teste com as proteções do navegador deliberadamente desativadas.
O que nenhum dos dois comunicados diz diretamente
A narrativa oficial de ambas as empresas nesta semana é otimista: a IA ajuda os humanos, a IA reforça a segurança, a IA faz o trabalho aborrecido. Tudo verdade. E ao mesmo tempo, há um subtexto que convém ler sem anestesia.
Que um modelo encontre 20% do trabalho anual de segurança de um projeto como o Firefox em catorze dias, um projeto que a Mozilla passa décadas a reforçar com engenheiros especializados, não é apenas uma história de progresso. É também uma história sobre o que acontece quando essa mesma capacidade é usada por alguém que não tem um acordo de divulgação coordenada com a Mozilla. A Anthropic escreve-o no seu próprio relatório: "Se os modelos futuros ultrapassarem a barreira entre descobrir vulnerabilidades e explorá-las, será necessário considerar medidas adicionais."
A transição da IA generativa para a IA agentiva, sistemas que não esperam, mas agem, está a ser anunciada há meses em conferências e artigos científicos. Esta semana aconteceu em produção, com faturas pagas e patches distribuídos a centenas de milhões de pessoas.
O mercado que já mudou de mãos antes do debate
O lançamento do GPT-5.4 coloca a OpenAI em competição direta com a Anthropic, que tinha dominado o segmento empresarial com ferramentas semelhantes; ambas as empresas competem para capturar o mercado corporativo com sistemas capazes de fazer trabalho real em setores dispostos a adotar IA.
| Métrica | GPT-5.4 (xhigh) | Claude Opus 4.6 (Sem raciocínio) | Análise |
|---|---|---|---|
| Criador | OpenAI | Anthropic | GPT-5.4 (xhigh) é desenvolvido pela OpenAI e Claude Opus 4.6 pela Anthropic |
| Janela de contexto | 1050k tokens (~1.575 páginas A4 com Arial 12) | 200k tokens (~300 páginas A4 com Arial 12) | GPT-5.4 (xhigh) tem uma janela de contexto significativamente maior |
| Data de lançamento | Março de 2026 | Fevereiro de 2026 | GPT-5.4 (xhigh) tem uma data de lançamento mais recente |
| Suporte a imagens | Sim | Sim | Ambos os modelos suportam entrada de imagens |
| Código aberto (pesos do modelo) | Não | Não | Ambos os modelos são proprietários |
A diferença é de posicionamento, não de capacidade técnica. A OpenAI entra no território empresarial com um modelo unificado que consolida todo o seu stack anterior. A Anthropic chega com uma demonstração prática de que o seu modelo pode atuar como auditor de segurança autónomo. O Llama 4 Maverick da Meta, com a sua janela de contexto de dez milhões de tokens, continua a ser a opção de referência para quem queira executar tudo na sua própria infraestrutura sem depender de nenhuma das duas.
O debate sobre se a IA substitui empregos ou os transforma continuará a ser debate por algum tempo. O que já não é debate é se consegue fazer o trabalho. Esta semana fez.
O que fica pendente é mais incómodo: saber quem mais, com acesso aos mesmos modelos, está a analisar os mesmos repositórios neste momento.
Fontes
As notícias mais importantes enquanto você aprecia um café.
Junte-se à nossa comunidade. Receba nossa análise semanal exclusiva antes de todos.
Notícias Relacionadas

TecnologíaGlobal
5 min de leitura
A NASA confirma a data e a ementa da Artemis II
A nave Orion não tem frigorífico nem reabastecimento. Por isso a NASA preparou 189 artigos únicos, amaranto como proteína, cinco tipos de molho picante e 43 chávenas de café para 10 dias em redor da Lua.

TecnologíaDinero
6 min de leitura
A Meta despede 16.000 pessoas. As suas ações sobem 3%
A Reuters confirmou os planos de corte de até 20% na força de trabalho da Meta. Wall Street celebrou a notícia com uma subida de 3%. Em 2026, a IA já justifica 55.775 despedimentos no setor tecnológico.

Tecnología
6 min de leitura
A Intel prometeu o mesmo há 18 meses. Agora regressa com mais núcleos, preço mais baixo e um truque de software
O Core Ultra 7 270K Plus chega com 24 núcleos e 5,5 GHz por 299 dólares a 26 de março. A verdadeira novidade não está no silício, mas sim numa ferramenta que reescreve o código dos jogos em tempo real para favorecer a Intel.











