Technology•6 min read
GPT-5.4 outperforms human experts in 83% of tasks: AI is no longer practicing, it's working

On March 5, OpenAI launched GPT-5.4 with a figure that does not leave much room for interpretation: on GDPval, the benchmark measuring real professional work across 44 occupations, the model matched or surpassed human specialists in 83% of comparisons. Three days later, Anthropic published that Claude Opus 4.6 had identified 22 new vulnerabilities in Firefox over two weeks, 14 of them high-severity, and that it found the first one in twenty minutes. Two different news stories. The same message.
GPT-5.4: the model that no longer waits for instructions at every step
GPT-5.4's architecture consolidates something OpenAI had been building in pieces: it unified the reasoning capabilities of GPT-5.2 with the agentic programming capabilities of GPT-5.3-Codex into a single model. The result is a system that operates computers autonomously, navigates applications unsupervised, and completes complex workflows without anyone needing to guide it step by step.
According to OpenAI, GPT-5.4 is 33% less likely to make errors in individual statements than its predecessor GPT-5.2, and complete responses contain 18% fewer errors. Performance numbers in professional environments are even more striking: on GDPval, which evaluates well-specified work across 44 occupations in the nine sectors contributing most to US GDP, GPT-5.4 reached 83% matching or exceeding human expert criteria, up from the 70.9% achieved by GPT-5.2.
For anyone working with financial documents, presentations, or legal analysis, this is not abstract. In investment and banking models, 87.3% of evaluators preferred GPT-5.4 compared to 68.4% who preferred GPT-5.2. The context window rises to one million tokens in the API, allowing entire contracts, code repositories, or clinical records to be ingested in a single interaction.
The key operational feature is a new function called forward planning: before responding, the model shows its reasoning plan. The user can redirect it mid-process without starting from scratch. That is not a minor detail. It is what distinguishes an assistant from a collaborator.
| Metric / Benchmark | GPT-5.4 | GPT-5.3-Codex | GPT-5.2 |
|---|---|---|---|
| GDPval (wins or ties) | 83.0 % | 70.9 % | 70.9 % |
| SWE-Bench Pro (Public) | 57.7 % | 56.8 % | 55.6 % |
| OSWorld-Verified | 75.0 % | 74.0 %* | 47.3 % |
| Toolathlon | 54.6 % | 51.9 % | 46.3 % |
| BrowseComp | 82.7 % | 77.3 % | 65.8 % |
* Previously reported as 64.7%. GPT-5.3-Codex reaches 74.0% with a newly introduced API parameter that preserves the original image resolution.
Claude found in Firefox what humans spent a year patching
While OpenAI was presenting its model, Anthropic was publishing something with a different dimension: not a benchmark number, but a real case with real consequences for hundreds of millions of users.
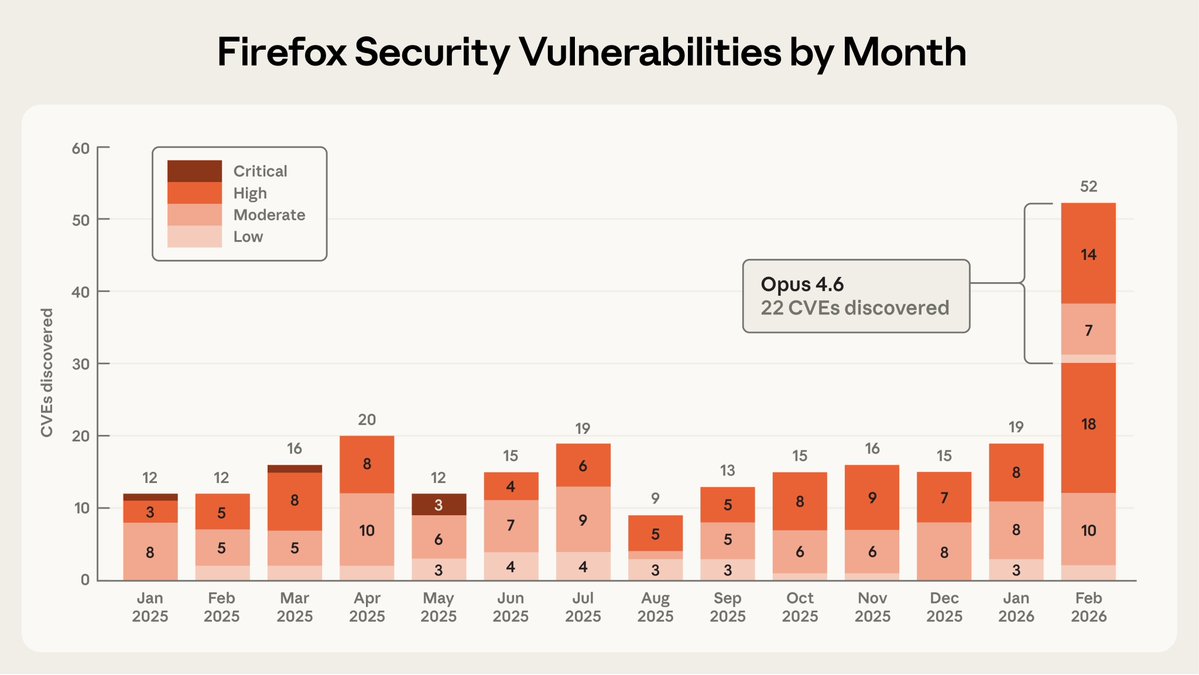
Claude Opus 4.6 found 22 vulnerabilities in Firefox during February 2026, more than were reported in any single month of 2025, and its fixes reached users through Firefox 148.0. Of those 22, 14 were classified as high-severity, representing nearly a fifth of all vulnerabilities in that category patched in Firefox throughout all of 2025.
The detail that has circulated most among security researchers: after just twenty minutes of autonomous exploration, the model reported having identified a "use-after-free" error in the browser's JavaScript engine, which was validated by a human researcher in a virtualized environment before being submitted to Mozilla.
Of the 112 total reports Anthropic sent to Mozilla, 22 resulted in official CVEs for security flaws, while the remaining ninety corresponded to non-critical issues such as crashes and logic errors. The team scanned around 6,000 C++ source files. The complete operation lasted two weeks.
Here comes the part that Anthropic did not highlight, but which the report makes clear: the model is far better at finding flaws than exploiting them. To test the system's offensive capabilities, researchers tried to have Claude develop functional exploits for the discovered flaws, spending approximately $4,000 in API credits over hundreds of attempts; Opus 4.6 only managed to create a working exploit in two cases. Both worked only in test environments with the browser's protections deliberately disabled.
What neither press release says directly
The official narrative from both companies this week is optimistic: AI helps humans, AI strengthens security, AI does the boring work. All true. And at the same time, there is a subtext worth reading without anesthetic.
That a model finds 20% of a project like Firefox's annual security work in fourteen days, a project that Mozilla has spent decades hardening with specialized engineers, is not only a story of progress. It is also a story about what happens when that same capability is used by someone who does not have a coordinated disclosure agreement with Mozilla. Anthropic writes it in its own report: "If future models break the barrier between finding vulnerabilities and exploiting them, additional measures will need to be considered."
The transition from generative AI to agentic AI, systems that do not wait but act, has been announced for months in conferences and papers. This week it happened in production, with paid invoices and patches distributed to hundreds of millions of people.
The market that already changed hands before the debate
The launch of GPT-5.4 puts OpenAI in direct competition with Anthropic, which had dominated the enterprise segment with similar tools; both companies are competing to capture the corporate market with systems capable of doing real work in sectors ready to adopt AI.
| Metric | GPT-5.4 (xhigh) | Claude Opus 4.6 (No reasoning) | Analysis |
|---|---|---|---|
| Creator | OpenAI | Anthropic | GPT-5.4 (xhigh) is developed by OpenAI and Claude Opus 4.6 by Anthropic |
| Context window | 1050k tokens (~1,575 A4 pages, Arial 12) | 200k tokens (~300 A4 pages, Arial 12) | GPT-5.4 (xhigh) has a significantly larger context window |
| Launch date | March 2026 | February 2026 | GPT-5.4 (xhigh) has a more recent launch date |
| Image input support | Yes | Yes | Both models support image input |
| Open source (model weights) | No | No | Both models are proprietary |
The difference is one of positioning, not technical capability. OpenAI enters enterprise territory with a unified model that consolidates its entire previous stack. Anthropic arrives with a practical demonstration that its model can act as an autonomous security auditor. Meta's Llama 4 Maverick, with its ten-million-token context window, remains the go-to option for those who want to run everything on their own infrastructure without depending on either company.
The debate about whether AI replaces jobs or transforms them will remain a debate for a while. What is no longer a debate is whether it can do the work. This week it did.
What remains pending is more uncomfortable: knowing who else, with access to the same models, is scanning the same repositories right now.
Sources
The most important news while you enjoy a cup of coffee.
Join our community. Get our exclusive weekly analysis before anyone else.
Related News

TecnologíaGlobal
5 min read
NASA confirms the date and menu for Artemis II
The Orion spacecraft has no refrigerator or resupply. That's why NASA designed 189 unique items, amaranth as protein, five types of hot sauce, and 43 cups of coffee for 10 days around the Moon.

TecnologíaDinero
5 min read
Meta lays off 16,000 people. Its stock rises 3%
Reuters confirmed plans to cut up to 20% of Meta's workforce. Wall Street celebrated the news with a 3% surge. In 2026, AI already justifies 55,775 layoffs in the tech sector.

Tecnología
6 min read
AI already solves centuries-old math. What your bank encrypts is being rebuilt from scratch.
AlphaEvolve surpassed any known human solution in 20% of 67 open mathematical problems. At the same time, the RSA encryption that protects banks and government networks has been in the process of replacement for months. Two converging transformations.











